Introduction
While scraping rental listings, it’s useful to verify that the scripts managed to grab all the offers. This is nice to have on simple fully loaded single page, but even nicer if the rental listings are set up as a infinite scroll page, which seem increasingly popular on real estate websites and require multiple calls from the scraper.
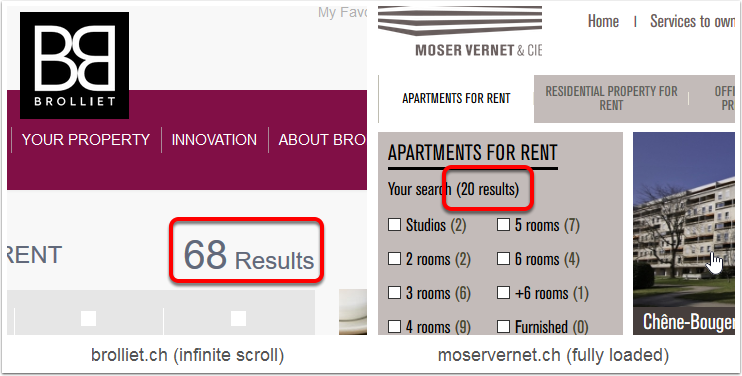
Count of offers on rental websites.
Even when they don’t load all the results, the websites nearly always indicate the number of matched offers. This can be used to verify that our final dataset has the correct number of rows.
Scraping the data
Scraping static content
Using our previous example, we can see that the number of matched offers is written on the page.

Count of offers can be found on the page.
Please keep in mind that I took the screenshot when I originally published the post and reran the code multiple times since. So the final scraped number might not match the screenshot.
Inspect the html of the page to find the id/class of the number of results and store it in a variable. We can complete the code as below:
# Load needed packages
suppressMessages(library(xml2))
suppressMessages(library(rvest))
# Create an html document
listing_url <- "https://www.moservernet.ch/en/apartments-for-rent/"
listing_html <- xml2::read_html(listing_url)
# Find the number of listed offers
listing_html %>%
html_node("#count-search") %>%
html_text()## [1] "()"Empty? It looks like the count is actually populated by a tiny bit of javascript, so it’s not available when we parse the page source.
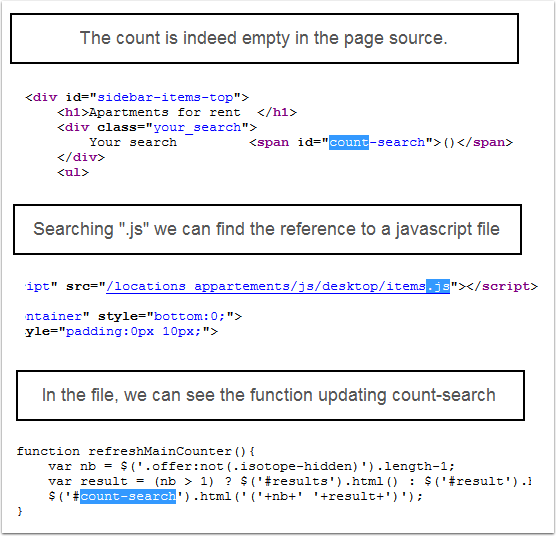
The counter is updated by Javascript.
Scraping content generated by javascript
xml2::read_html by itself cannot inspect the content generated by javascript. For that we can use another library splashr. In a nutshell, splashr lets you spin and interact with a splash headless browser in a docker container. If this sounds like jibberish, let’s try a translation:
- “spin and interact with a headless browser”: create a virtual browser (we won’t see it, it happens in the background) that will browse/render the page and give us back it’s content (including the javascript generated content). “Splash” is one these headless browsers, but you might have heard of another one named “phantomJS”.
- “in a docker container”: think of docker is a way to easily run lightweight virtual machines (called container). So rather than installing splash and all its python dependencies, we will run a virtual machine with splash installed in it and destroy it when we are done, leaving our main system untouched.
Installing docker is beyond the scope of this post, but there are tons of ressource online. At the time of this writing, to install splashr and docker (the package that manages docker from R), you need to grab them from github.
The github page of docker (the R package) explains how to install the python package docker. Yes, you read that well: in order to use splash (the scrapping python lib), splashr uses:
docker(the R package),
So proceed in steps:
- Install
docker(the engine) - Install
docker(the python lib) in a virtualenv like explained here - Install the R packages
devtools::install_github("bhaskarvk/docker")
devtools::install_github("hrbrmstr/splashr")- Let RStudio know that you want python commands to be run in this virtualenv
# Use the path where you installed the docker venv
library(reticulate)
use_virtualenv("~/.virtualenv/docker", required=T)The very first time we run splashr, it might be a bit slow: it will have to download the docker image (the template used to create container) that has Splash installed in it. The image is documented here.
suppressMessages(library(splashr))
install_splash()## Pulling from scrapinghub/splash## Digest: sha256:08c9b401fb812c9bf6591773c88c73b0c535336b97dd1ac04f9dbb988b2a7f76## Status: Image is up to date for scrapinghub/splash:3.0We can then use splashr to create a splash container and get the html, this time with javascript generated content in it. The xml2 functions can still be used on the html returned by splashr.
I added a wait time of two seconds between start_splash and render_html because I kept getting errors looking like render_html was called before the container was fully operational.
splash_container <- splashr::start_splash()
Sys.sleep(2)
listing_html_js <- splashr::render_html(url = listing_url)
count <- listing_html_js %>%
html_node("#count-search") %>%
html_text()
print(paste("count value is:", count))## [1] "count value is: (21 results)"The number is extracted with a little regular expression and the stringr package:
offer_number <- stringr::str_extract(count, "[0-9]+")
print(paste("offer_number value is:", offer_number))## [1] "offer_number value is: 21"Don’t forget to stop and delete your container.
stop_splash(splash_container)We now have the expected number of offers, which we can use to verify our final dataset (read previous post to see how).