Introduction
The offers on real estate websites aren’t always in an easy-to-use format, especially if you want to compare offers from multiple agencies.
In a previous post, we saw how to scrape a listing of apartments on a single page with R. However, listings usually do not include all the details about the items. They usually only list a condensed version of the information and a url to a “detail” page, which contains the rest of the fields. For example, we could not add any insight about “Floors” to our dataset as “Floor” is only detailled on each apartement details page. In this post, we will see how to:
- find the URL for each apartment
- scrape details found on each details page
- combine these details into a single dataframe
- merge this detail dataframe with our original dataframe
Scraping the data
Getting the URLs for each apartment
# Load needed packages
suppressMessages(library(xml2))
suppressMessages(library(rvest))# Create an html document
listing_url <- "https://www.moservernet.ch/en/apartments-for-rent/"
listing_html <- xml2::read_html(listing_url)
# Find all the nodes with class "offer" in id "offers"
offers <- listing_html %>%
html_nodes("#offers .offer")
# Extract the first target url of each first link in each node
offers_urls <- offers %>%
html_node("a") %>%
html_attr("href")
head(offers_urls)## [1] "/en/apartments-for-rent/cornavin-1-5-rooms--0570.42.0030"
## [2] "/en/apartments-for-rent/grand-pre-1-5-rooms--7259.40.0010"
## [3] "/en/apartments-for-rent/chene-bougeries-1-5-rooms--2652.41.0010"
## [4] "/en/apartments-for-rent/paquis-2-rooms--0630.40.0010"
## [5] "/en/apartments-for-rent/servette-2-5-rooms--2078.31.0010"
## [6] "/en/apartments-for-rent/grand-saconnex-3-rooms--2018.44.0040"Using one example to map our scraping
Using the first link as an example, we can explore how the data should be scraped.
offer_url <- offers_urls[1]
offer_url## [1] "/en/apartments-for-rent/cornavin-1-5-rooms--0570.42.0030"The id of each offer is actually available directly in the URL.
id <- offer_url %>%
sub(".*([0-9]{4}\\.[0-9]{2}\\.[0-9]{4}).*",
"\\1", .)
id## [1] "0570.42.0030"Next we need to scrape the data contained at this URL. As links are relative, we start by rebuilding the full link, which we use with xml2::read_html().
# Create full URL for offer
BASE_URL <- "https://www.moservernet.ch"
offer_full_url <- paste0(BASE_URL, offer_url)
# Scrape HTML for offer
offer_html <- xml2::read_html(offer_full_url)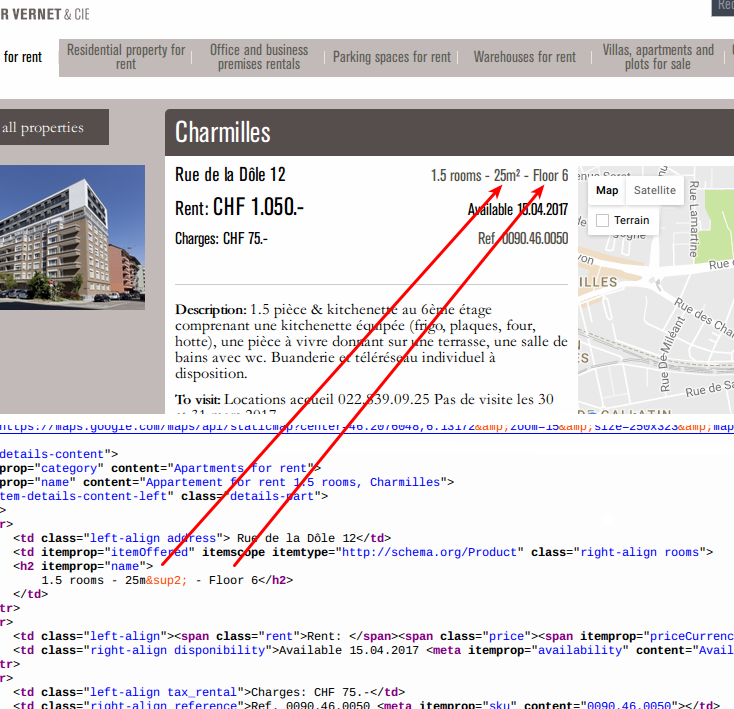
Screenshot of source code for apartment detail webpage
Looking at the source code, we can see that the attributes we are after (“Floor” and “Surface area”) are located in the same node: a h2 tag contained in a td tag with itemprop=itemOffered.
offer_attr <- offer_html %>%
html_node("[itemprop=itemOffered]") %>%
html_text() %>%
stringr::str_trim() %>%
stringr::str_split(" - ", simplify = T) %>%
as.vector()
offer_attr## [1] "1.5 rooms" "36m²" "Floor 2"With a bit more parsing, we can get clean numbers.
# Find floor data by finding the vector element
# containing text "Floor" and isolating the
# number next to it.
floor <- grep("Floor", offer_attr, value = T) %>%
stringr::str_replace("Floor","") %>%
stringr::str_trim()
floor## [1] "2"# Find surface area data by finding the vector
# element containing text "m²" and isolating the
# number next to it.
surface <- grep("m²", offer_attr, value = T) %>%
stringr::str_replace("m²","") %>%
stringr::str_trim()
surface## [1] "36"However, if we look closely at the list of urls, there seem to be two types of URLs.
table(sub("(/.*/.*/).*","\\1",offers_urls)) %>%
tibble::as_tibble() %>%
setNames(c("URL start with:","n")) ## # A tibble: 2 x 2
## `URL start with:` n
## <chr> <int>
## 1 /en/apartments-for-rent/ 15
## 2 /en/residential-property-for-rent/ 7Most URLs follow the pattern /en/apartments-for-rent/<address>--<id> but a few look like /en/residential-property-for-rent/<address>--<id>. If we open one, we can see that the page layout is different.
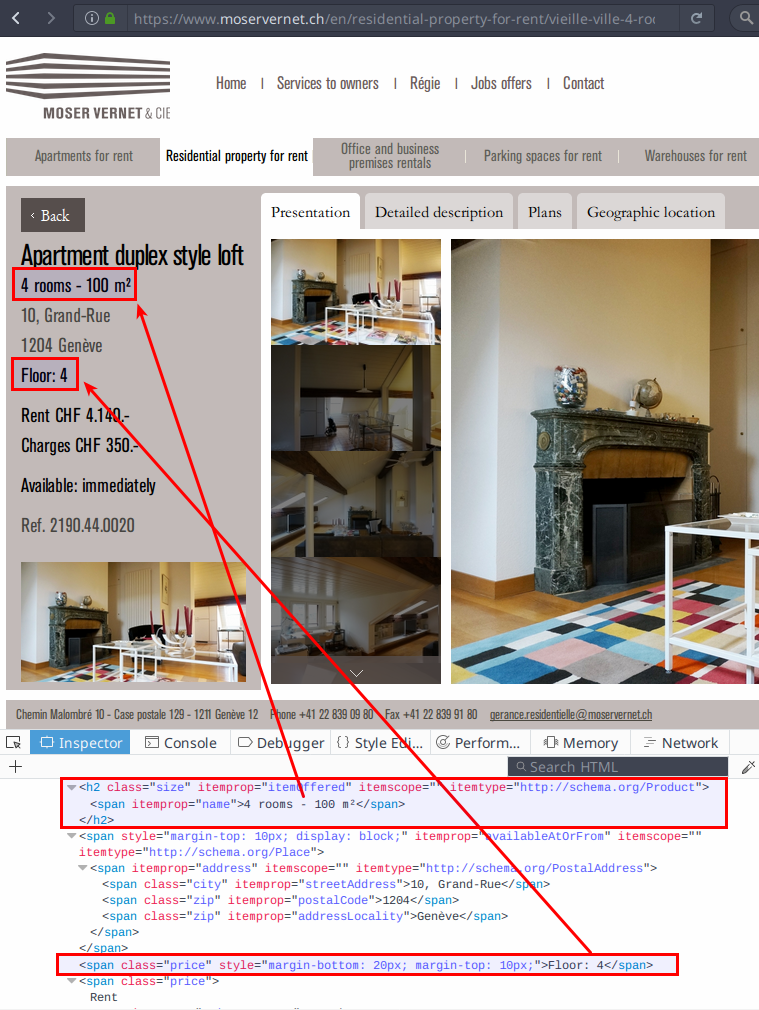
Screenshot of source code for residential detail webpage
The surface area is still available in a node with [itemprop=itemOffered], but the floor is in another node, which seem to be the first node with class price. With a bit of rewriting on the floor code, we can adapt to the 2 different layouts:
# The code below can find the floor on both layout types,
# which are identified by a pattern in their url.
floor <- ifelse(
grepl("apartments", offer_url),
grep("Floor", offer_attr, value = T),
offer_html %>%
html_node(".price") %>%
html_text()) %>%
stringr::str_replace("Floor[:]{0,1}","") %>%
stringr::str_trim() %>%
as.numeric()Scraping all links with reusable code
We can now put all our code together in a function and use it on each link. Note that the slow_scrape_extra_info wrapper just make sure we wait for a little while between each request.
scrape_extra_info <- function(offer_url) {
BASE_URL <- "https://www.moservernet.ch"
offer_full_url <- paste0(BASE_URL, offer_url)
offer_html <- xml2::read_html(offer_full_url)
offer_attr <- offer_html %>%
html_node("[itemprop=itemOffered]") %>%
html_text() %>%
stringr::str_trim() %>%
stringr::str_split(" - ", simplify = T) %>%
as.vector()
list(
id = offer_url %>%
sub(".*([0-9]{4}\\.[0-9]{2}\\.[0-9]{4}).*",
"\\1", .),
floor = ifelse(
grepl("apartments", offer_url),
grep("Floor", offer_attr, value = T),
offer_html %>%
html_node(".price") %>%
html_text()) %>%
stringr::str_replace("Floor[:]{0,1}","") %>%
stringr::str_trim() %>%
as.numeric(),
surface = grep("m²", offer_attr, value = T) %>%
stringr::str_replace("m²","") %>%
stringr::str_trim() %>%
as.numeric()
)
}
slow_scrape_extra_info <- function(offer_url) {
Sys.sleep(sample(1:15/10,1))
scrape_extra_info(offer_url)
}
# Apply the function to each url that contains an offer id
# and store the results into a single dataframe
extra_info <- grep(".*([0-9]{4}\\.[0-9]{2}\\.[0-9]{4}).*",
offers_urls, value = T) %>%
purrr::map(slow_scrape_extra_info) %>%
dplyr::bind_rows() %>%
na.omit()
knitr::kable(head(extra_info))| id | floor | surface |
|---|---|---|
| 2454.44.0030 | 4 | 24 |
| 2040.41.0020 | 1 | 44 |
| 2066.41.0010 | 1 | 48 |
| 0510.45.0030 | 5 | 55 |
| 2457.41.0020 | 1 | 50 |
| 2018.48.0020 | 8 | 58 |
Thanks to the common id field, we can join this dataframe with the one obtained in the previous post.